
이 글들은 백준 온라인 저지의 백준님이 2020년 1~2월에 강의하시는 강의 내용을 듣고 복습한 뒤 간단하게 정리하여 올리는 글이다. 이 글을 쓰는 이유는 그날그날 들은 강의 내용을 복습하고 정리함으로써 배운 것을 확실히 머리에 남김과 동시에 나중에 다시 상기시킬 때 도움이 되도록 하기 위함이다.
● 수학 2
○ 행렬
두 행렬을 더하는 데 걸리는 시간 : O(NM)
두 행렬이 NxM, MxK일때 C[i][j] = ∑A[i][k]*A[k][j]
두 행렬을 곱하는 데 걸리는 시간 : O(NMK)
O(N^3)인데 1초안에 수행하려면 N≤500이어야 한다.
행렬 제곱
행렬 A^B제곱
곱셈의 횟수 = O(logB)
A^B = AxAxAxAx...xAxA (B번)
곱셈 한번 하는데 걸리는 시간 = N^3
총 시간복잡도 O(N^3logB)
※ 몰라도 상관없지만 알아두면 좋은 것들
○ 피보나치 수
앞에서는 수가 작아도 뒤에서 수가 급격히 커진다.
45번째 피보나치 수는 29억?
long long을 쓰면 좋다.
비사노 주기
피보나치 수를 K로 나눈 나머지는 반드시 주기를 갖는다.
피보나치 수는 D[i] = D[i-1] + D[i-2]로 구할 수 있기 때문에
계속 구하다가 한번이라도 같은 쌍이 나오면 ( [0, k-1], [0, k-1] 같은 ) 계속 같은 수가 나온다.
N번째 피보나치 수를 M으로 나눈 나머지는 N%K번째 피보나치 수와 같다.
피보나치6 문제
10^18번째 피보나치 수를 구할 때 행렬을 이용해야 한다.
Fn = Fn-1 + Fn-2
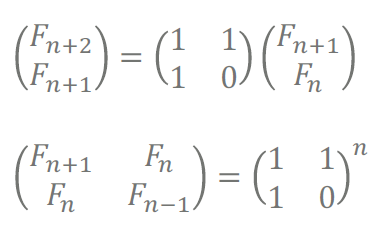
○ 이항계수
nCm = n! / m!(n-m)!
가끔 구현해야 할 일이 있다.
파스칼의 삼각형 문제
n행 r열 값 = C[n][r] = nCr
nCk = n개 중에서 k개를 뽑는 경우의 수
다이나믹으로 접근하면
① n번을 뽑는 경우
② n번을 뽑지 않는 경우
그 외.
○ 포함배제의 원리
○ 오일러의 피함수
○ 확장 유클리드 알고리즘
● 자료구조 2
- 스택
- 유니온 파인드
- 힙
- BST
유니온파인드는 이분탐색을 할 때 좋은 자료구조긴 한데 삽입, 삭제에 매우 안좋아서 안 쓴다. 그래서 그 개량형인 BST를 이분탐색에 쓴다.
○ 이진 검색 트리
왼쪽의 모든 값은 루트보다 작아야하고, 오른쪽의 모든 값은 루트보다 커야한다.
검색에 걸리는 시간 = O(h). 높이만큼 걸린다.
삽입과 검색은 거의 같은 코드를 공유한다.
링크드 리스트를 써서 구현
삭제가 좀 까다롭다.
1. 자식이 0개인 경우
하나만 지우면 된다.
2. 자식이 1개인 경우
자식을 부모에 이어 붙이면 된다.
3. 자식이 2개인 경우
실제로 노드를 지우진 않고 들어있는 값을 변경한다.
지우려는 값의 바로 다음에 오는 값으로 바꾸면 된다.(인오더 순서)
한번 오른쪽으로 간 뒤에 계속 왼쪽으로 간다. 노드가 없을 때까지.
지우려는 노드와 교환한뒤 해당 노드를 삭제해 주면 된다.
모든 연산에 걸리는 시간이 높이 O(h)만큼 걸린다. 검색, 삽입, 삭제
그래서 느리기 때문에 잘 사용하지 않는다. 어떻게 저장하느냐에 따라 트리 모양이 달라지기 때문. 높이가 최대 N
균형을 잘 맞추면 좌우 높이의 차이가 0이거나 1이다. 그러면 높이가 logN
균형 있는 트리 : AVL-Tree, Red-Black Tree, Splay Tree, Treap 등이 있다. but 구현이 어려워서 잘 안쓴다.
라이브러리는 C++ STL의 set을 쓰면 된다.
○ 힙
최대값 또는 최소값만 의미가 있을 때, 그리고 그 값만 사용을 할 때 사용한다.
삽입 : 아무거나
삭제 : 최대값, 최소값
모든 시간복잡도 O(logN)
( BST는 삽입, 삭제, 검색 : 아무거나)
최대힙 삽입
가장 마지막 위치에 새로운 수를 넣는다.
부모와 계속해서 비교해가며 루트 < 자식이면 두 수를 바꿔준다.
최대힙 제거
루트를 가장 마지막에 있는 값으로 변경
자식과 비교하면서 아래로 내려간다.
연산 O(h) = O(logN)
C++의 힙은 최대힙이고, Java의 힙은 최소힙이다.
c++에서 최소힙을 구현할 수는 있지만 범위가 자료형 전체일 때는 사용할 수 없다. x==-x인 경우가 있어서
△ 가운데를 말해요
N개의 수가 주어졌을 때 지금까지 나온 수의 중간값을 구하는 문제
[5] → 5
[5, 3] → 3
[5, 3, 4] → 4
[5, 3, 4, 2] → 3
[5, 3, 4, 2, 6] → 4
방법1
값을 입력 받을 때마다 매번 수를 정렬하고 가운데 있는 값을 출력하는 방법
O(N^2logN)이란 시간이 걸린다.
수가 추가될때 마다 정렬하므로 N * NlogN. 시간초과
방법2
리스트를 사용해서 N^2만에 구할 수 있다.
이 방법은 정렬을 사용하지 않는다.
앞에서 쭉 보다가 입력한 수를 추가할 위치를 찾아서 넣는다.
이것도 시간제한에 걸린다.
방법3
힙을 사용
수를 N/2, N/2개로 나눠서 왼쪽과 오른쪽으로 나눠서 푼다.
L 배열 : 최대힙, R 배열 : 최소힙
항상 왼쪽과 오른쪽 크기의 차이가 1보다 작거나 같게 만든다.
왼쪽에 있는 모든 수는 루트보다 작다.
왼쪽과 오른쪽은 모두 N/2로 나눠져야 한다.
가운데 값은 항상 L배열의 최대값 또는 R배열의 최소값
짝수 : 0, 홀수: 1차이가 나도록
수를 추가할 뿐. 그리고 그에 걸리는 시간은 logN
따라서 총 시간복잡도 O(NlogN)
힙은 위와 같이 삭제가 안될 경우에 쓴다. 수가 계속 추가되기만 할 뿐 삭제하지는 않았다.
○ 유니온 파인드
상호 배타적 집합
2가지 연산으로 이루어져 있다.
Find : x가 어떤 집합에 포함되어 있는지 찾는 연산
Union : x와 y가 포함되어 있는 집합을 합치는 연산
구현은 트리
P[i] = i의 부모
Union(x, y) = y의 부모를 x로 만든다. = Parent[y] = x
보통 Union에서는 이미 부모가 있을 수 있기 때문에 루트끼리 합친다.

위 그림에서 Union(2, 5) = Union(1, 4)와 같다. 각각의 부모가 1과 4.
구현이 쉬운 알고리즘 중 하나
문제점
트리가 일자가 되면 Find를 했을 때 시간복잡도가 노드의 개수와 같아지게 된다.
높이가 N이 되어버려서 시간복잡도가 O(N)이 된다.
Union 연산의 시간복잡도는 Find에 달려있다. Find연산의 두배
해결법
Find를 하면서 만난 모든 parent값을 루트로 바꿔준다.
트리의 높이가 매우 크게 줄어든다.
=경로압축


랭크 : 높이와 같은 의미를 갖지만, 경로압축을 사용하면 높이와 다른 값을 가질 수도 있다. 즉, 원래 높이라는 뜻
랭크가 작은 것을 랭크가 높은 것의 자식으로 만든다.
유니온파인드는 오직 합치기만 할때 사용하기 좋다. 분리하는거 X
△ 바이러스
여러가지 방법이 있다.
① DFS
② BFS
③ 최단거리 알고리즘
1에서 모든 정점 거리 구하기.
N이 200제한이라 어떤 알고리즘도 다 시간 통과가 가능하다.
적절한 방법은 아니지만 N이 작아서 가능하다.
④ 유니온 파인드
합치고 합치고 합친뒤 1인 개수를 구하면 된다.
● 다이나믹 프로그래밍 2
△ 이동하기
NxM 크기의 미로에서 (1, 1)에서 (N,M)으로 이동할 때 가져올 수 있는 사탕의 최대 개수
방법 1
D[i][j] = (1, 1)시작 (i, j) 도착 합의 최대
아래와 오른쪽으로만 갈 수 있다.
① 위에서 왔을 때
(1, 1) → (i-1, j) → (i, j)
D[i][j] = D[i-1][j]
② 왼쪽에서 올때
(1, 1) → (i, j-1) → (i, j)
D[i][j] = D[i][j-1]
③ 대각선
다 합치면, D[i][j] = max( D[i-1][j], D[i][j-1], D[i-1][j-1]) + a[i][j]
& 범위검사
방법2
D[i][j] = (1, 1) 시작 (i, j) 도착
대부분 마지막꺼가 빠지면 무슨일이 일어날까, 식으로 품
화살표를 끝을 기준으로 푼다. (i, j)에 있는 사탕을 가지고 (i, j+1)로 간다. (i+1, j), (i+1, j+1)도 가능
D[i][j+1] = D[i][j] + A[i][j+1] 이런식으로
but, 대각선으로 가는 건 의미가 없다. A[i][j]>=0이기 때문에 오른쪽을 거쳐가는게 항상 낫다. = 방법3
D[i][j+1] = D[i][j] + A[i][j+1]
D[i+1][j] = D[i][j] + A[i+1][1]
방법3
대각선 이동은 처리하지 않는다. 다른 2가지 방법보다 항상 작다.
방법 4
재귀함수 이용
△ 팰린드롬?
앞에서 읽을때 = 뒤에서부터 읽을때 인 문자를 '팰린드롬'이라 한다.
예) '토마토', '다시합시다', 'level', 'eve'
문자열 S가 팰린드롬인지 아닌지 판별하는 문제
방법
① 문자열 S == 문자열 S를 뒤집은 것
시간복잡도 O(N)
② S[i] == S[n-i-1]
0≤i≤N/2
시간복잡도 O(N)
이 문제는 어떤 수열의 부분 수열이 팰린드롬인지 아닌지 판별하는 문제
팰린드롬인지 확인하는데 걸리는 시간 : O(N)
질문이 M개면 O(NM)
재귀적으로 이용
A[0] == A[7]
--------------> A[1]~A[6]까지가 팰린드롬임을 증명
A[1] == A[6]
A[2] == A[5]
A[3] == A[4]
즉, (i~j) 팰린드롬이면
① A[i] == A[j]
② A[i+1]~A[j-1]이 팰린드롬
위 두가지 조건을 만족한다.
길이가 1일때, 항상 팰린드롬
길이가 2일때, 두 문자가 같으면 팰린드롬
그 이상일 때, A[i] == A[j]이고, A[i+1]~A[j-1]이 팰린드롬이면, A[i]~A[j]는 팰린드롬이다.
시간복잡도 O(N^2)
'공부 > 백준 2020년 1~2월 알고리즘' 카테고리의 다른 글
| 11번째 수업 (0) | 2020.02.12 |
|---|---|
| 9번째 수업 (0) | 2020.02.05 |
| 8번째 수업 (0) | 2020.01.31 |
| 7번째 수업 (0) | 2020.01.29 |
| 6번째 수업 (0) | 2020.01.23 |